IBM Watson을 이용한 이미지 학습 및 인식하기
IBM Watson을 이용하여 특정 이미지 학습 후 인식하기
IBM Watson을 이용하면 다양한 AI 기능들을 사용할 수 있다.현재 Watson은 Conversation, Language Translator, Personality Insights, TTS(Text to Speech), STT(Speech to Text) 및 Visual Recognition 등이 제공된다.(IBM Watson 기능들)
이번 글에서는 이미지에서 의미를 찾을 수 있는 Visual Recognition 기능을 살펴보고, 특정 이미지들을 학습하여 인식하는 과정을 소개한다.
Watson Visual Recognition의 자세한 소개는 아래 IBM Bluemix 사이트에서 참고한다.
Visual Recognition
IBM Bluemix에서 소개된 Visual Recognition 소개는 다음과 같다.
Visual Recognition
시각적 컨텐츠에서 의미를 찾습니다! 장면, 사물, 얼굴 및 기타 컨텐츠에 대한 이미지를 분석합니다. 제공되는 기본 모델을 선택하거나 사용자 고유의 사용자 정의 클래스류를 작성할 수 있습니다. 콜렉션 내에서 비슷한 이미지를 찾습니다. 특정 장면을 이해하기 위해 이미지나 동영상 프레임의 시각적 컨텐츠를 분석하는 스마트 애플리케이션을 개발합니다.
기능
- 일반 분류
- 이미지를 설명하는 클래스 키워드를 생성합니다. 고유의 이미지를 사용하거나 분석을 위해 공개적으로 액세스 가능한 웹 페이지에서 관련 이미지 URL을 추출합니다.
- 얼굴 감지
- 이미지에서 얼굴을 감지합니다. 또한 이 서비스에서는 얼굴의 나이 범위 및 성별에 대한 일반적인 표시도 제공합니다.
- 시각적 훈련
- 고유한 사용자 정의 시각적 클래스류를 작성합니다. 이 서비스를 사용하여 일반 분류에 사용할 수 없는 사용자 정의 시각적 개념을 인식합니다.
- 비슷한 이미지 검색(BETA)
- 업로드 후 시각적으로 비슷한 이미지를 찾기 위해 이미지 콜렉션을 검색합니다.
Visual Recognition 사용하기
Watson Visual Recognition을 사용하기 위해서는 먼저 IBM Bluemix에 가입해야 한다. 3개월 무료로 사용할 수 있다.
STEP1. IBM Bluemix에 가입되었다면 콘솔화면 왼쪽 메뉴 아이콘을 누리고, 아래와 같이 Watson 메뉴를 선택 후 'Watson 서비스 작성' 항목을 선택한다.


STEP2. 다양한 Watson 기능 중에 Visual Recognition 을 선택한다.

STEP3. Visual Recognition 기능을 만들기 위해 필요한 정보를 입력 후 아래 '작성' 버튼을 누르면 서비스가 생성된다.

STEP4. 다음은 Visual Recognition을 사용하여 어떤 결과를 얻을 수 있는지를 알려주는 정보이다.

STEP5. Visual Recognition 이 생성되면 다음과 같이 세 개의 기본 툴이 생성된다.
- Default
- 다양한 정보들을 얻을 수 있다.
- Food
- 음식관련하여 상세한 정보를 얻을 수 있다.
- Face Detection
- 사람의 나이, 성별 등의 정보를 얻을 수 있다.

다음은 각 분류자에 사진을 입력했을 때 각 분류자들에서 어떤 정보들을 표시하는지 보여준다.

Visual Recognition를 이용하여 학습 및 특정 이미지 인식
위 세 개의 분류자들보다 특정 정보를 인식하도록 분류자를 추가해서 관련 사진들을 학습시킬 수 있다. 이렇게 되면 원하는 정보만을 뽑을 수 있는 분류자를 새롭게 만들 수 있게 된다. 학습을 시키기 위해서는 최소 20개의 사진이 필요하다.
이번에 만들 분류자는 우산과 우산을 쓴 사람을 학습시킬 예정이다. 분류는 추가할 수 있다. 사진은 .zip 파일로 압축하여 업로드 시켜야 하며, 현재 분류자(Classifier) 이름은 영어로 입력해야 한다.
새로운 분류자 이름을 'Umbrella'로 하고, '우산'과 '우산 쓴 사람' 두 개의 분류를 만들어 학습시킨다.
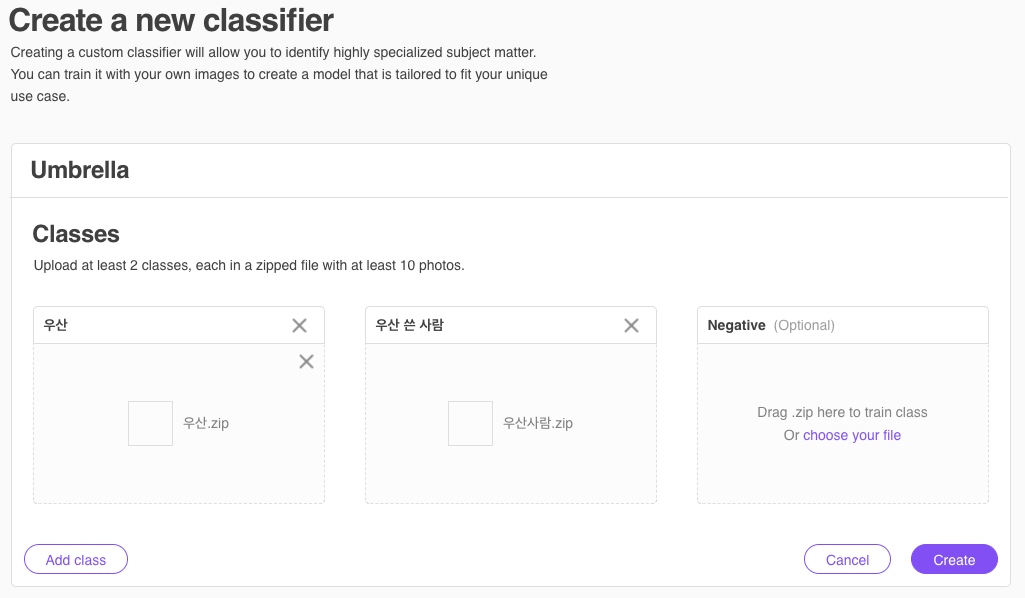
STEP2. 'Create' 버튼을 누르면 분류자가 생성되며, '학습중(training)' 이라는 상태가 표시된다.

STEP3. 학습이 종료되면 'ready' 상태가 되어 사진 파일을 업로드해서 분석할 수 있다.

STEP4. 우산과 우산 쓴 사진을 입력하면 각각 다음과 같이 인식 값 정도를 표시한다. 학습 데이터가 부족해서 그런지 0.55를 넘기지는 못했다.




댓글
댓글 쓰기